近年来,在大数据计算领域最火热的开源计算框架无疑是Spark,那么什么是Spark?Spark相比于其它框架又又哪些优势?本文将对这些问题一一进行解释。
一、Spark概述
1、什么是Spark
Apache Spark™ is a unified analytics engine for large-scale data processing
Apache Spark是专为大规模数据处理而设计的快速通用的计算引擎。
Hadoop MapReduce 由于其设计初衷并不是为了满足循环迭代式数据流处理,因此在多并行运行的数据可复用场景(如:机器学习、图挖掘算法、交互式数据挖掘算法)中存在诸多计算效率等问题。所以 Spark 应运而生,Spark就是在传统的 MapReduce 计算框架的基础上,利用其计算过程的优化,从而大大加快了数据分析、挖掘的运行和读写速度,并将计算单元缩小到更适合并行计算和重复使用的RDD计算模型。
2、Spark发展历史
- 2009年,Spark 框架诞生于 UC Berkeley AMP Lab (加州大学伯克利分校AMP实验室)
- 2010年,加州大学伯克利分校正式开源 Spark 框架,并成立 Databricks 公司提供基于 Spark 的云服务
- 2013年,Databricks 公司将 Spark 捐赠给 Apache 基金会
- 2014年,Spark 成为 Apache 顶级项目
- 2016年,Spark 发布 2.0 版本
- 2020年,Spark 发布 3.0 版本
3、Spark的优势
(1)速度快
- 内存计算下,Spark 比 Hadoop 快100倍

(2)使用简单
- Spark 采用 Scala 语言编写,支持Java、Scala、Python、R 和 SQL

(3)通用性
- Spark 结合了SQL、流和复杂分析,为SQL处理、流式处理、机器学习和图计算提供了强大的支持

(4)运行在任何地方
- Spark 可部署运行在 Hadoop、Apache Mesos、Kubernetes、standalone 和 云服务中

4、Spark核心模块
Spark 的核心模块包括 Spark Core、Spark SQL、Spark Streaming、Spark MLlib 和 Spark GraphX,下面将用一张图来说明核心模块之间的关系:

(1)Spark Core
Spark Core 中提供了 Spark 最基础与最核心的功能,Spark 其他的功能如:Spark SQL、Spark Streaming,、GraphX 和 MLlib 都是在Spark Core 的基础上进行扩展的。
(2)Spark SQL
Spark SQL 是 Spark 用来操作结构化数据的组件。通过Spark SQL,用户可以使用 SQL 或者 Apache Hive 版本的 SQL方言(HQL)来查询数据。
(3)Spark Streaming
Spark Streaming 是 Spark 平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的API。
(4)Spark MLlib
MLlib 是 Spark 提供的一个机器学习算法库。MLlib 不仅提供了模型评估、数据导入等额外的功能,还提供了一些更底层的机器学习原语。
(5)Spark GraphX
GraphX 是 Spark 面向图计算提供的框架和算法库。
二、Spark快速入门
接下来将通过一个入门案例来介绍如何使用 Spark 框架。在编写程序之前请确保计算机中已有 JDK 和 Scala SDK,Scala SDK 下载地址:https://www.scala-lang.org/download/。
0、案例
假设我们有1.txt和2.txt两个文件,这两个文件的内容如下:
(1)文件1.txt:
1 | Hello World |
(2)文件2.txt:
1 | Hello World |
现在要求统计两个文件中每个单词出现的次数,那么用 Spark 框架该如何去实现该功能呢?
1、创建项目
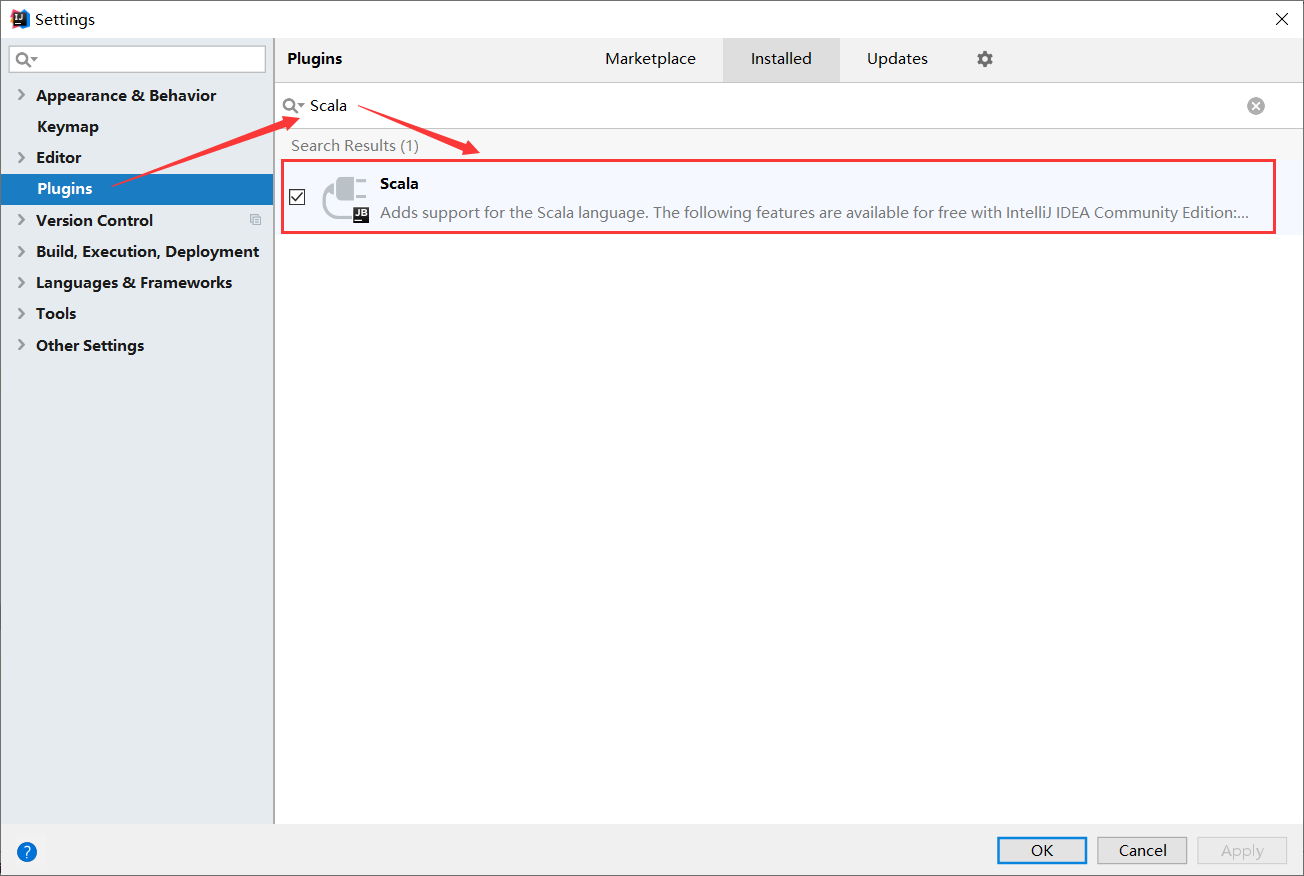
(1)添加Scala插件
以IDEA为例,需要在 Settings -> Plugins 中搜索”Scala”,并安装该插件
(2)添加依赖
在Maven项目的pom.xml文件中添加以下内容:
1 | <dependencies> |
2、实现功能
首先在项目的根目录下创建一个dataset文件夹,将1.txt和2.txt放入到该文件夹下,之后编写一个WordCount单例对象,代码如下:
1 | package cn.frankfang.spark |
之后运行项目便可在控制台中看到输出的结果:

但如果出现以下结果:
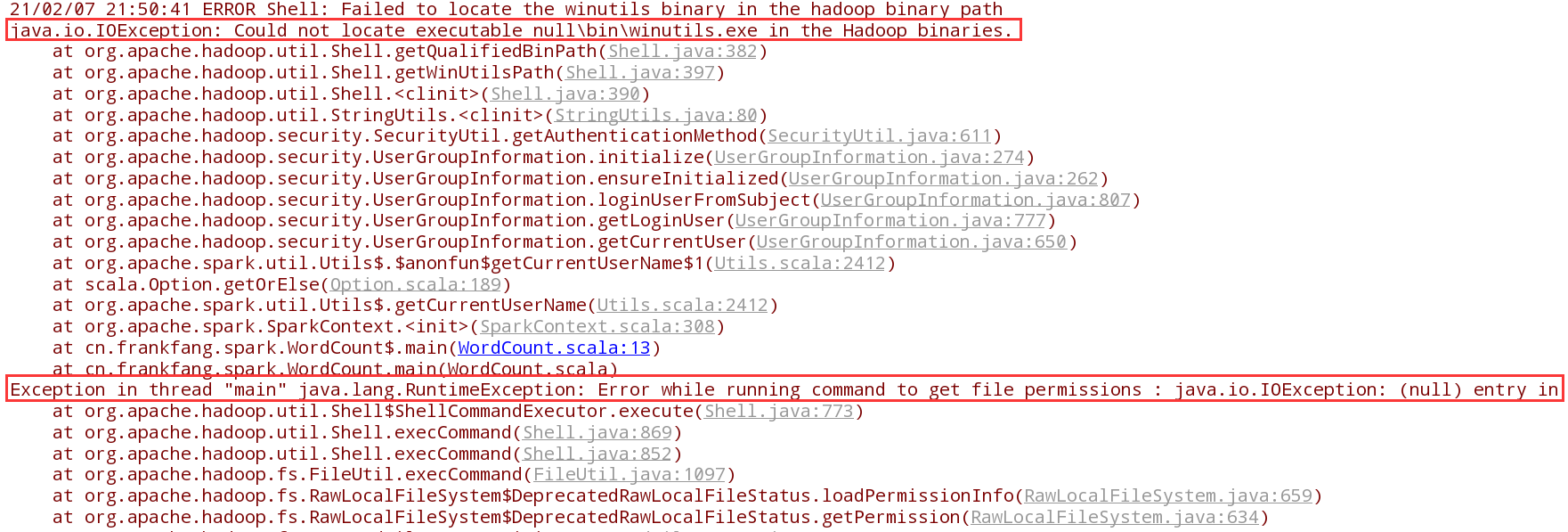
这就说明系统中没有配置 Hadoop 的环境变量,因此需要将 Hadoop 的安装路径添加到环境变量中,在添加完环境变量之后重启IDEA,再次运行程序便可正确输出结果。