二分查找
一、基本概念折半查找又称二分查找(Binary Search),它仅适用于有序的顺序表。
折半查找的基本思想是:首先将给定的关键字与表中中间位置的元素比较,若相等,则查找成功,返回该元素的存储位置;若不等,则所需查找的元素只能在中间元素以外的前半部分或后半部分。然后在缩小的范围内继续进行同样的查找,如此重复,直到找到为止,或确定表中没有所需要查找的元素,则查找不成功,返回查找失败的信息。
二、算法实现二分查找的Java语言实现如下,完整的实现已上传至Gitee,仓库地址:https://gitee.com/fzcoder/data-structure-and-algorithms-demo。
12345678910public static int binarySearch(int[] arr, int key) { int low = 0, high = arr.length - 1; while (low <= high) { int mid = (low + high) / 2; // 取中间位置 if (arr[ ...
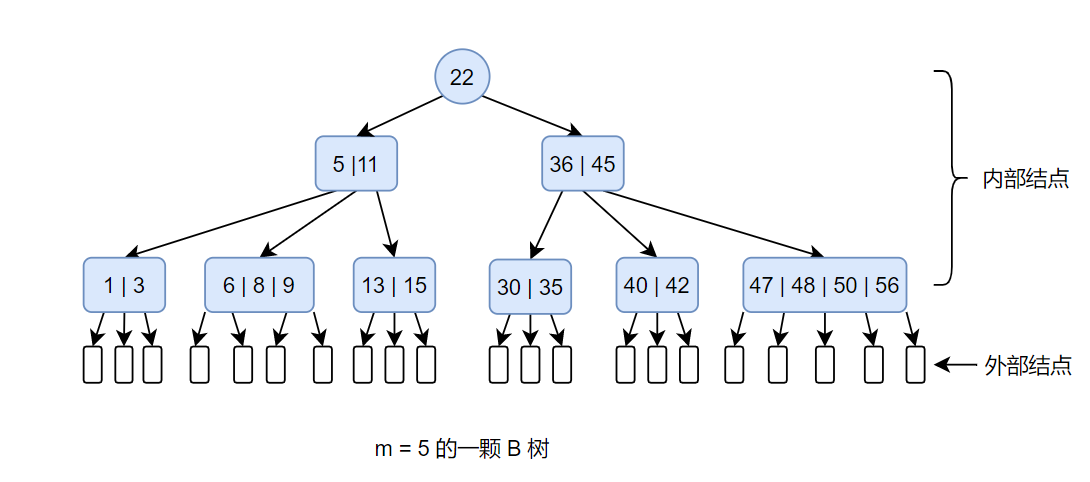
B树和B+树
一、B树1、基本概念B 树是为磁盘或其他直接存取的辅助存储设备而设计的一种平衡搜索树。B 树类似于红黑树,但它们在降低磁盘I/O操作数方面要更好一些。许多数据库系统使用 B 树或者 B 树的变种(如 B+树)来存储信息。
B 树中所有结点的孩子个数的最大值称为 B 树的阶,通常用 m 表示,一棵 m 阶 B 树或为空树,或是具有以下性质的 m 叉树:
在每个结点中含有n个关键字$key_1, key_2, …, key_n$,以非降序存放,使得$key_1\le key_2\le …\le key_n$。
关键字$key_i$对存储在各子树中的关键字范围加以分割,如果$k_i$为任意一个存储在以当前结点为根结点的子树中的关键字,则有:$k_1\le key_1\le k_2\le key_2\le …\le k_n\le key_n\le k_{n+1}$。
每个叶子结点具有相同的深度。
每个结点所包含的关键字个数有上界和下界。除了根结点以外的所有非叶子结点至少有$\lceil m/2 \rceil - 1$个关键字,至多有$m-1$个关键字。
由上述性质的第四点可知,除了根结点以 ...
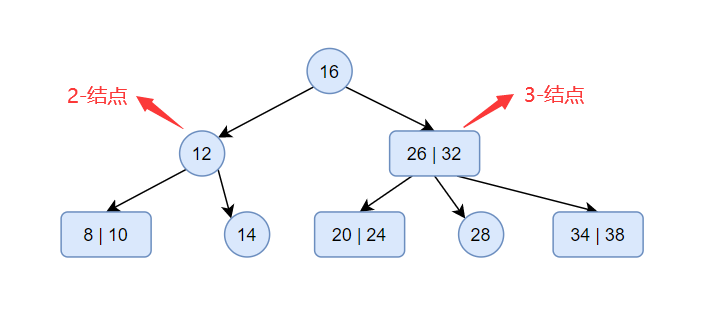
2-3树
一、基本概念2-3树是最简单的 B 树结构,其每个非叶节点都有两个或三个子女,而且所有叶子结点都在同一层上。2-3树不是二叉树,其节点可拥有3个孩子。
在2-3树中包含2-结点和3-结点,下面分别对这两个结点进行解释:
2-结点:含有一个键(及其对应的值)和两条链,左链接指向2-3树中的键都小于该结点,右链接指向的2-3树中的键都大于该结点。
3-结点:含有两个键(及其对应的值)和三条链,左链接指向的2-3树中的键都小于该结点,中链接指向的2-3树中的键都位于该结点的两个键之间,右链接指向的2-3树中的键都大于该结点。
二、查找将二叉搜索树的查找算法一般化我们就能够直接得到2-3树的查找算法。 要判断一个键是否在树中,我们先将它和根结点中的键比较。如果它和其中任意一个相等,查找命中;否则我们就根据比较的结果找到指向相应区间的连接,并在其指向的子树中递归地继续查找。如果这个是空链接,查找未命中。
例如在上图中的2-3树中查找结点28,下面给出查找过程:
三、插入1、向2-结点插入新结点往2-3树中插入元素和往二叉搜索树中插入元素一样,首先要进行查找,然后将节点挂到未找到的结点 ...
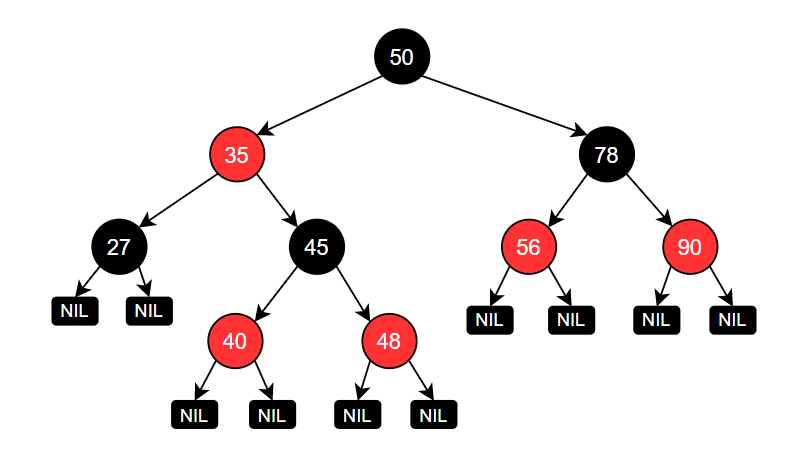
红黑树
一、基本概念红黑树(red-black tree) 是一棵二叉搜索树,它在每个结点上增加了一个存储位来表示结点的颜色,可以是RED或BLACK。通过对任何一条从根到叶子的简单路径上各个结点的颜色进行约束,红黑树确保没有一条路径会比其他路径长出2倍,因而是近似于平衡的。
红黑树具有以下性质:
每个结点或是红色的,或是黑色的。
根结点是黑色的。
每个叶结点(NIL)是黑色的。
如果一个结点是红色的,则它的两个子结点都是黑色的。
对每个结点,从该结点到其所有后代叶结点的简单路径上,均包含相同数目的黑色结点。
一颗典型的红黑树如下图所示(其中的NIL可以理解为空指针):
一棵有 n 个内部结点的红黑树的高度至多为$2log_2(n+1)$。关于该结论的证明,可以参阅《算法导论》中的相关证明,这里不再进行赘述。
二、旋转指针结构的修改是通过旋转(rotation)来完成的,这是一种能保持二叉搜索树性质的搜索树局部操作。下图给出了两种旋转:左旋和右旋。
下面来简单介绍一下左旋和右旋是如何实现的:
1、左旋
2、右旋
三、插入这里先挖个坑,有时间再回来填,这里先推荐几个介绍红黑树的文章和视频 ...
平衡二叉树
一、基本介绍为避免树的高度增长过快,降低二叉排序树的性能,规定在插入和删除二叉树的结点时要保证任意结点的左、右子树的高度差的绝对值不超过 1,将这样的二叉排序树称为平衡二叉树(Balanced Binary Tree),又称AVL树。
定义结点左子树与右子树的高度差为该结点的平衡因子,则平衡二叉树结点的平衡因子的值只可能是 -1、0 或 1。
二、插入操作二叉排序树保证平衡的基本思想为:每当在二叉排序树中插入(或删除)一个结点时,首先检查其插入路径上的结点是否因为此次操作而导致了不平衡。若导致了不平衡,则先找到插入路径上离插入结点最近的平衡因子的绝对值大于 1 的结点 N,再对以 N 为根的子树,在保持二叉排序树特性的前提下,调整各结点的位置关系,使之重新达到平衡。
平衡二叉树的调整存在LL平衡旋转(右单旋转)、RR平衡旋转(左单旋转)、LR平衡旋转(先左后右双旋转)、RL平衡旋转(先右后左双旋转)这4种情况,下面将分别介绍这几种情况下的调整方法。
(1)LL平衡旋转假设有一颗平衡二叉树,当该二叉树插入一个结点 6 时,根节点的平衡因子的绝对值大于 1,此时该二叉树不再是一颗平衡二叉树 ...
进程与线程
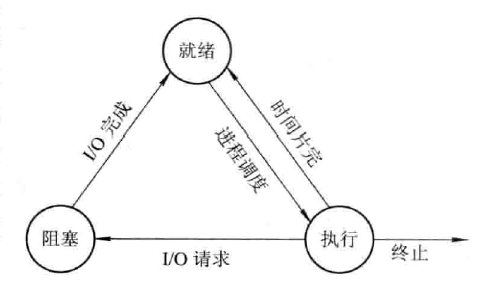
一、进程1、基本概念计算机上所有可运行的软件,通常也包括操作系统,被组织成若干顺序进程(sequential process),简称进程(process)。 一个进程就是一个正在执行程序的实例,包括程序计数器、寄存器和变量的当前值。从概念上说,每个进程拥有它自己的虚拟 CPU。当然,实际上真正的 CPU 在各进程之间来回切换。但为了理解这种系统,考虑在(伪)并行情况下运行的进程集,要比试图跟踪 CPU 如何在程序间来回切换简单得多。
在上图 (a) 中可以看到,在一台多道程序计算机的内存中有 4 道程序。
在上图 (b) 中,这 4 道程序被抽象为 4 个各自拥有自已控制流程(即每个程序自己的逻辑程序计数器)的进程,并且每个程序都独立地运行。当然,实际上只有一个物理程序计数器,所以在每个程序运行时,它的逻辑程序计数器被装人实际的程序计数器中。当该程序执行结束(或暂停执行)时,物理程序计数器被保存在内存中该进程的逻辑程序计数器中。
在上图 (c) 中可以看到,在观察足够长的一段时间后,所有的进程都运行了,但在任何一个给定的瞬间仅有一个进程真正在运行。即在单核 CPU 中进程是并发 ...
二叉排序树
一、基本概念二叉排序树(Binary Sort Tree, BST)也称二叉搜索树,或是一颗空树,或者是具有一下性质的二叉树:
若左子树非空,则左子树上所有结点的值均小于根结点的值。
若右子结点非空,则右子树上所有结点的值均大于根结点的值。
左、右子树也分别是一颗二叉排序树。
根据二叉排序树的定义有:左子树结点值 < 根结点值 < 右子树结点值,所以对二叉排序树进行中序遍历,可以得到一个递增的有序序列。
如上图所示,该二叉排序树的中序遍历序列为 1 2 3 4 5 6。
二、相关操作1、二叉排序树的插入二叉排序树作为一种动态树表,其特点是树的结构通常不是一次生成的,而是在查找过程中,当树中不存在关键字值等于给定值的结点时再进行插入的。
首先确定二叉排序树结点的数据结构及成员方法:
123456789101112131415161718192021222324252627282930313233class TreeNode { int val; TreeNode left; TreeNode right; public TreeNode ...
图
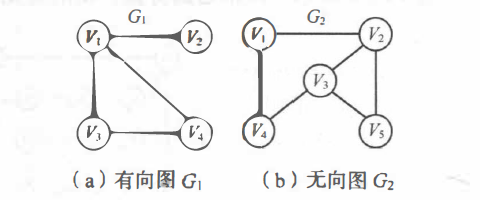
一、图的基本概念1、基本定义图(Graph)G 由两个集合 V 和 E 组成,记为 G = ( V, E ),其中 V 是顶点的有穷非空集合,E 是 V 中顶点偶对的有穷集合,这些顶点偶对称为边。V(G )和 E(G) 通常分别表示图 G 的顶点集合和边集合,E(G) 可以为空集。若 E(G) 为空,则图 G 只有顶点而没有边。
对于图 G,若边集 E(G) 为有向边的集合,则称该图为有向图;若边集 E(G) 为无向边的集合,则称该图为无向图。
2、相关术语数据结构中图的相关术语与离散数学中的基本相同,这里不再赘述。
二、图的存储结构1、邻接矩阵邻接矩阵(Adjacency Matrix)是表示顶点之间相邻关系的矩阵。设 G(V, E) 是具有 n 个顶点的图,则 G 的邻接矩阵是具有如下性质的 n 阶方阵:
例如本文第一张图中的 G1 和 G2 的邻接矩阵如下所示:
对于带权图来说,若顶点 vi 和 vj 之间有边相连,则邻接矩阵中对应项存放着该边对应的权值,若顶点 Vi 和 Vj 不相连,则用 ∞ 来代表这两个顶点之间不存在边:
其中,Wij表示边上的权值;∞ 表示计算机允 ...
树与二叉树
一、树1、基本定义树(Tree)是 n(n 大于等于 0)个结点的有限集。它或为空树(n = 0),或为非空树(n > 0),对于非空树 T:
有且仅有一个称之为根的结点。
除根结点以外的其余结点可分为 m(m > 0)个互不相交的有限集 T1,T2,…,Tm,其中每一个集合本身又是一棵树,并称为根的子树。
树具有以下特点:
树的根结点没有前驱,除根结点外的所有结点有且仅有一个前驱。
树中所有结点可以有零个或多个后继。
2、相关术语
结点:树中的一个独立单元。包含一个数据元素及若干指向其子树的分支,如上图 (b) 中的 A、B、C、D 等。
结点的度:结点拥有的子树数称为结点的度。例如,A 的度为 3,C 的度为 1,, F 的度为 0。
树的度:树的度是树内各结点度的最大值。上图 (b) 所示的树的度为 3。
叶子:度为 0 的结点称为叶子或终端结点。结点 K、L、F、G、M、1、J 都是树的叶子。
双亲和孩子:结点的子树的根称为该结点的孩子,相应地,该结点称为孩子的双亲。例如,B 的双亲为 A,B 的孩子有 E 和 F。
兄弟:同一个双亲的孩子之间互 ...
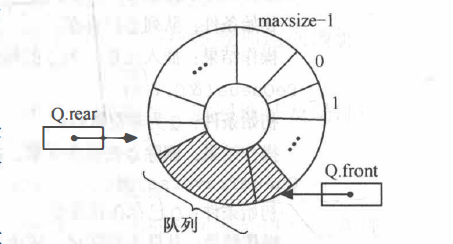
栈和队列
一、栈1、基本概念栈(Stack)是只允许在表尾进行插入和删除操作的线性表。对栈来说,表尾端称为栈顶(top),表头端称为栈底(Bottom)。不含元素的空表称为空栈。栈的示意图如下:
栈的修改是按后进先出的原则进行的,因此栈又称为后进先出(Last In First Out, LIFO)的线性表。
栈有如下的基本操作:
操作
说明
init(&S)
初始化一个空栈
isEmpty(S)
判断一个栈是否为空,若为空返回true,否则返回false
push(&S, x)
进栈
pop(&S, &x)
出栈
getTop(S, &x)
读栈顶元素
destroy(&S)
销毁栈
2、存储结构栈是一种操作受限的线性表,类似于线性表,它也有对应的两种存储方式。
(1)顺序栈采用顺序存储的栈称为顺序栈。它利用一组地址连续的存储单元存放自栈底到栈顶的数据元素,同时附设一个指针指向当前栈顶元素的位置。用C语言可对顺序栈作如下定义:
1234567#define MAXSIZE 50 // 定义栈中元素的最大个数t ...