Java并发编程:线程安全
一、基本概念1.1 定义当多个线程访问某个类时,不管运行时环境采用何种调度方式或者这些线程将如何交替执行,并且在主调代码中不需要任何额外的同步或协同,这个类都能表现出正确的行为,那么就称这个类是线程安全的。
1.2 无状态对象如果只是看上面的定义是无法弄清楚什么是线程安全的,因此我们需要举一些例子来进行说明,就比如说Java Web开发中经常使用的Servlet,一般来说Servlet是单例的(也可以是多例的,但这里我们只讨论单例的情况), 实例中的方法会被多个线程进行调用,因此Servlet要保证其是线程安全的。所以Servlet通常都被设计成无状态的,下面给出一个例子:
123456789101112public class StatelessServlet implments Servlet { // ... @Override public void service(ServletRequest req, ServletResponse resp) { int i = handleReq(req); ...

MySQL入门:安装与使用
一、简介MySQL是目前最流行的开源的关系型数据库管理系统(RDBMS,Relational Database Management System)。
MySQL 由瑞典 MySQL AB 公司开发,目前属于 Oracle 公司。MySQL 是一种关联数据库管理系统,关联数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。
MySQL 是开源的,目前隶属于 Oracle 旗下产品。
MySQL 支持大型的数据库。可以处理拥有上千万条记录的大型数据库。
MySQL 使用标准的 SQL 数据语言形式。
MySQL 可以运行于多个系统上,并且支持多种语言。这些编程语言包括 C、C++、Python、Java、Perl、PHP、Eiffel、Ruby 和 Tcl 等。
MySQL 对PHP有很好的支持,PHP 是目前最流行的 Web 开发语言。
MySQL 支持大型数据库,支持 5000 万条记录的数据仓库,32 位系统表文件最大可支持 4GB,64 位系统支持最大的表文件为8TB。
MySQL 是可以定制的,采用了 GPL 协议,你可以修改源码来 ...
Java并发编程:创建线程
一、Thread1、基本介绍Thread类位于java.lang包中,是Java中表示线程的一个类,实现了Runnable接口。Thread类中常用的方法如下:
方法
说明
public Thread()
创建一个新线程
public Thread(String name)
创建一个指定名称的新线程
public Thread(Runnable target)
创建一个带有指定目标的新线程
public Thread(Runnable target, String name)
创建一个带有指定目标和名称的新线程
public void start()
开启当前线程
public void run()
执行当前线程任务
public String getName()
获取当前线程名称
public static void sleep(long millis)
使当前执行的线程在指定的毫秒数内休眠
public static Thread currentThread()
返回当前正在执行的线程的引用
public final void se ...
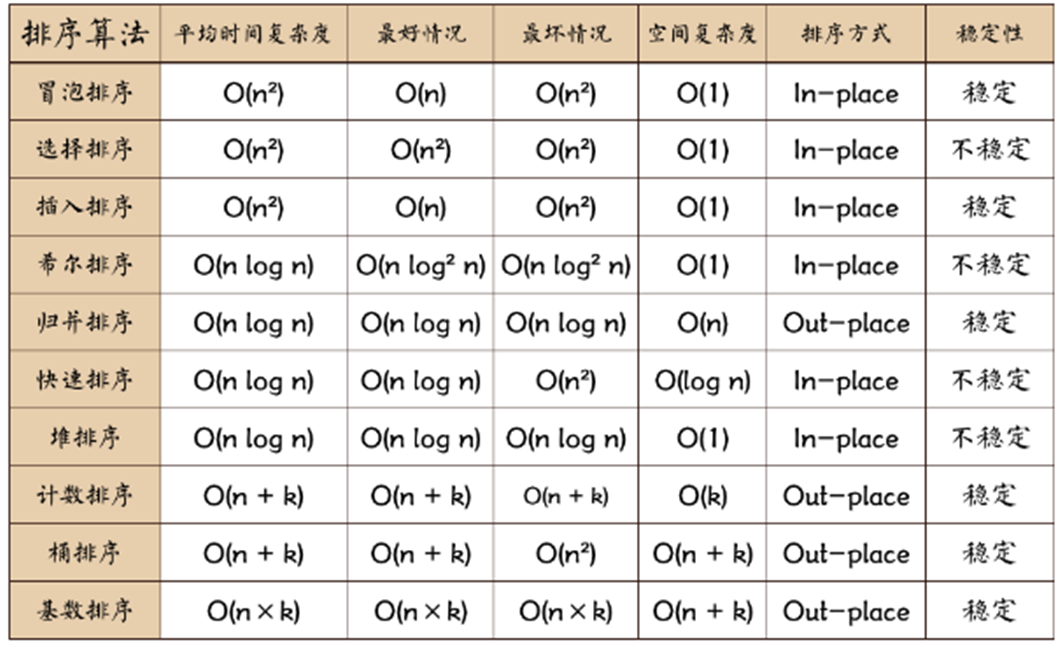
几种常见的排序算法
一、插入排序插入排序是一种简单直观的排序方法,其基本思想是每次将一个待排序的记录按其关键字大小插入前面已排好序的子序列,直到全部记录插入完成。下面将介绍几种常见的插入排序算法。
1、直接插入排序这是一种最简单的插入排序算法。假设当前索引为 i,在这之前的为有序序列,在这之后的为无序序列,我们要做的就是把当前索引为 i 的元素插入到前面的有序序列中,组成一个新的有序序列,之后将索引向后移动一位,重复上述操作,直到整个序列为有序序列。
12345678910111213141516171819// 直接插入排序void insert_sort(int* arr, int length){ for(int i = 1; i < length; i++) { // 有序队列的末尾下标 int insert_idx = i-1; // 待插入的数 int insert_val = arr[i]; // 寻找待插入的位置 while(insert_idx >= 0 &am ...
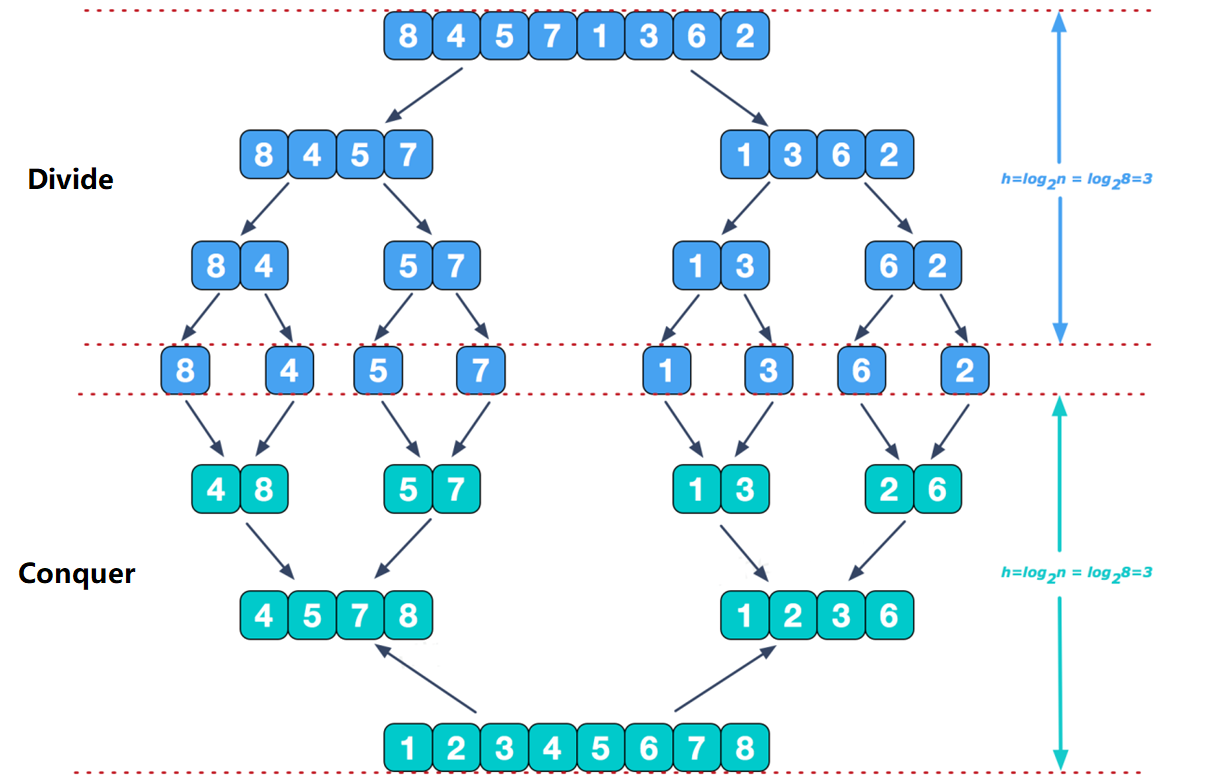
归并排序
一、基本概念归并排序(Merge Sort) 是建立在归并操作上的一种有效,稳定的排序算法,该算法是采用分治法(Divide and Conquer) 的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。
二、具体实现1、divide分(divide)的过程很简单,只需不断的从中间划分序列即可。代码实现如下:
123456789101112public static void mergeSort(int[] arr, int low, int high, int[] temp) { if (low < high) { // 从中间划分两个子序列 int mid = (low + high) / 2; // 对左侧子序列进行递归排序 mergeSort(arr, low, mid, temp); // 对右侧子序列进行递归排序 mergeSort(arr, mid + 1, high, temp); // ...

优先队列
一、基本概念队列是一种先进先出的数据结构,元素在队列尾追加,而从队列头删除。而在优先队列(Priority Queue) 中,元素被赋予优先级。当访问元素时,具有最高优先级的元素最先删除。优先队列具有最高级先出 (first in, largest out)的行为特征。通常采用堆这种数据结构来实现。
通常,优先队列包括最大优先队列和最小优先队列。最大优先队列可以确保每次获取到整个队列中的最大元素并将其删除,而最小优先队列则确保每次获取到整个队列中的最小元素并将其删除。
二、具体实现1、基本功能我们可以创建一个PriorityQueue<E>类来表示优先队列,下面将分别介绍一下该类的成员变量和公共方法:
成员变量
成员名
类型
说明
queue
Object[]
用于存放队列中的元素
size
int
当前队列中元素的个数
comparator
Comparator<? super E>
比较器,用于支持自定义比较
公共方法
方法名及参数
返回值类型
说明
isEmpty()
boolean
判断队列是否为空
size( ...

堆排序
一、基本概念1、堆堆(heap) 是一个数组,它可以被看成一个近似的完全二叉树。树上的每一个结点对应数组中的一个元素,除最底层外,该树是完全充满的,而且是从左向右填充的。
二叉堆可以分为两种形式:最大堆和最小堆。在这两种堆中,结点的值都要满足堆的性质,但一些细节定义则有所差异。在最大堆中,最大堆性质是指除了根以外的所有结点都要满足$parent.val \ge node.val$,也就是父结点大于等于子结点;而最小堆正好相反,即除了根以外的所有结点都要满足$parent.val \le node.val$,也就是父结点小于等于子结点。
2、堆排序堆排序(heap sort),顾名思义,就是一种通过堆实现排序的算法,在堆排序中使用的是最大堆。堆排序的基本思想如下:
将待排序的序列构造成一个最大堆,此时整个序列的最大值就是堆顶的根节点。
将其与末尾元素进行交换,此时末尾就为最大值。
然后将剩余$n-1$个元素重新构造成一个最大堆, 这样会得到剩余$n-1$个元素的最大值。
如此反复执行,便能得到一个有序的序列。
接下来我们将介绍堆排序的具体实现。
二、具体实现1、建堆首先我们需要做的 ...
快速排序
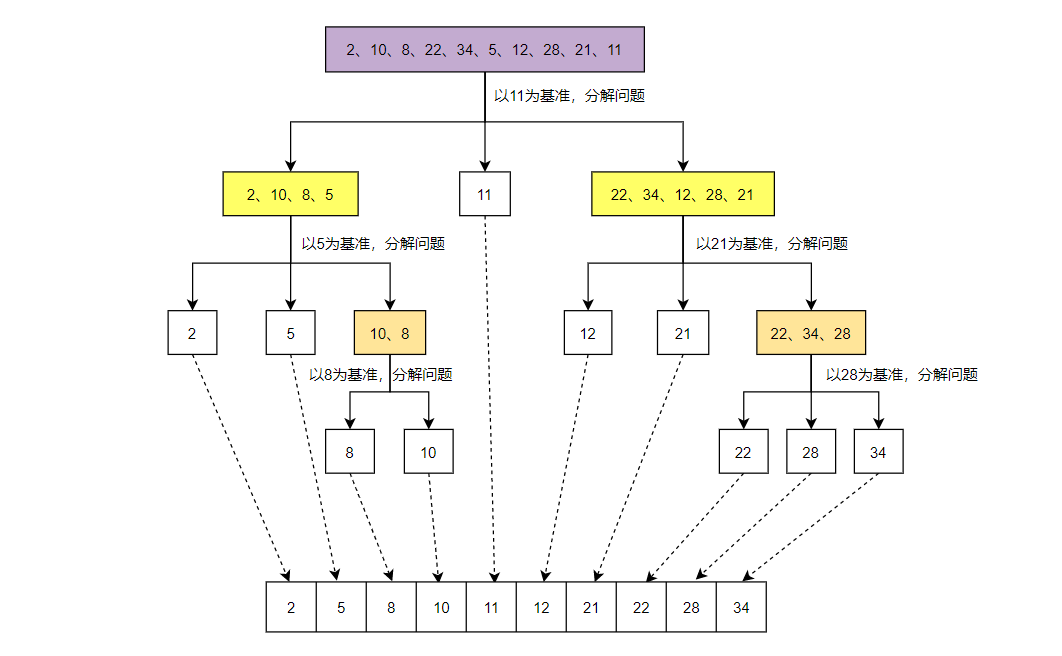
一、基本概念快速排序(Quick Sort) 的基本思想是基于分治法的,该算法通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
二、具体实现由上图可知,在每一趟快速排序中,都需要选择一个元素将待排序表划分为两部分,这个用来划分待排序表的元素叫做主元(pivot element),或者叫做基准。一趟快速排序的过程是一个交替搜索和交换的过程,下面通过实例来进行介绍。
1、操作过程假设有一个待排序的数组$= {49, 38, 65, 97, 76, 13, 27}$,我们选择数组的首个元素 49 作为主元,下面是一趟快速排序的过程:
指针 high 向前搜索,找到第一个小于主元49的元素27,并将其交换到 low 所指位置
指针 low 向后搜索,找到第一个大于主元49的元素65,并将其交换到 high 所指位置
指针 high 继续向前搜索找到第一个小于主元49的元素13,并将其交换到 low 所指位置
指针 low ...
几种常见的查找算法
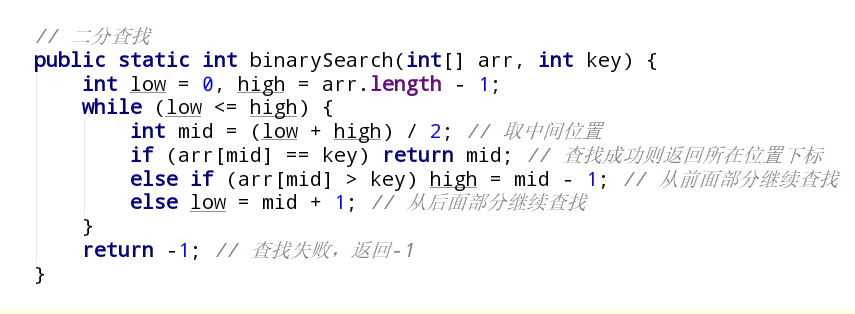
一、线性表的查找1、顺序查找顺序查找(Sequential Search)又称线性查找,它对顺序表和链表都是适用的。对于顺序表,可通过数组下标递增来顺序扫描每个元素;对于链表,可通过指针域来依次扫描每个元素。
查找表的数据结构如下:
12345typedef struct{ ElemType *elem; // 元素空间的基地址 int length; // 表的长度}SSTable;
顺序查找的算法如下:
1234567int seq_search(SSTable st, ElemType key){ int i; st.elem[0] = key; // 哨兵 for(i = st.length; st.elem[i] != key; --i); // 从后向前找 return i; // 若表中不存在关键字为key的元素,将查找到i为0时退出for循环}
在上述算法中使用了一个“哨兵”,即st.elem[0],目的是使得算法内的循环不必判断数组是否会越界。引入“哨兵”可以避免很多不必要的判断语 ...
散列表
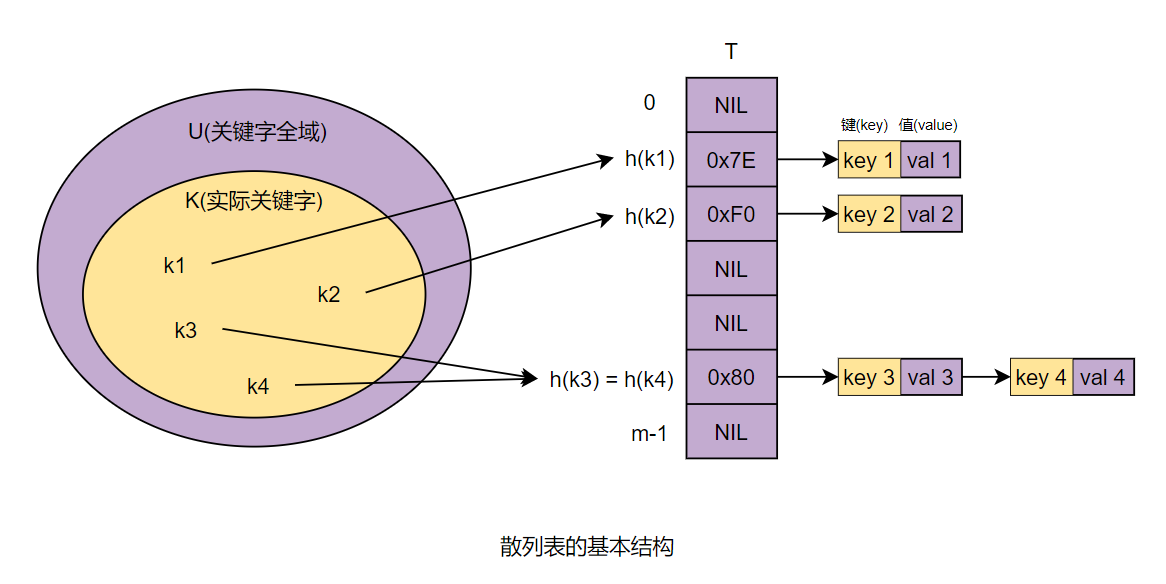
一、基本概念散列表(Hash Table) 也叫哈希表,是根据关键码值(Key Value)而直接进行访问的数据结构。它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度,这个映射函数叫做散列函数。散列表建立了关键字和存储地址之间的一种直接映射关系。
当关键字全域 U 较小时,我们可以使用一个称为直接寻址表(direct-address table)的数组表示一个取自关键字全域的动态集合,其中每个位置称之为槽(slot),对应全域 U 中的一个关键字,槽 k 指向集合中一个关键字为 k 的元素。
但当关键字全域 U 比较大时,这样做显然是不合适的,因为这样的话直接寻址表的空间开销会很大,而且很大概率会浪费很多空间(取决于实际关键字的数量,如果数量相对于关键字全域很少,那么就会造成大量空间的浪费)。
因此,我们需要用散列函数根据关键字来计算出槽的位置。这样,散列函数 h 就将关键字的全域 U 映射到散列表$T[0..m-1]$的槽位上。散列表的大小 m 一般比关键字全域 U 小得多,这样就解决了当使用直接寻址表时造成的大量空间浪费的问题。但是这样做又会出现一个新的问题,假如不 ...